
Benchmarking and Profiling are crucial techniques used to quantify the performance of code and measure improvements in its execution. In Python, understanding the performance of different implementations or comparing the efficiency of algorithms is essential, especially in scenarios where optimization is vital.
When trying to optimize code, it is important to remember that the time required to optimize the code, might be better spent on other tasks. This is to say, when developing code the primary goal is to deliver working code. Delivering fast and efficient code is a secondary goal. With this in mind, it is important not to prematurely optimize code. One can spend an incredible amount of time trying to optimize code before it even works! Furthermore, one could spend hours of work to save only seconds of run time. A balance needs to be struck!
A suitable development workflow would look something like this:
- Get a working instance of the code.
- Determine suitable benchmarks for evaluating the code (run time, iterations/second, iterations/cpu cores, precision on output, memory usage etc), and set target performance goals (e.g. total run time, total memory budget, etc).
- Evaluate the performance using the predefined benchmarks.
- If performance goals aren’t met, profile the code to determine where the bottle necks are and whether changes can be made.
- Implement suitable changes to the code and repeat from step 3.
Optimizing code can be a very time consuming process. There is a balance that needs to be made between acceptable run time and developer hours needed. Making multiple changes to the code at once can also introduce bugs that might be difficult to debug. Either make small iterative changes to the code, or make sure the code passes pre-defined tests after each development cycle.
Python provides the timeit module, which enables the measurement of execution time for specific code segments. This module offers a simple yet effective way to evaluate the performance of individual code snippets or functions:
%%timewill time the contents of an entire cell with a single run%%timeitwill time the contents of an entire cell, averaging over multiples run of that cell%timewill time a single line with a single run%timeitwill time a single line, averaging over multiples run of that cell
timeit will also suspend some features, such as the garbage collector, to get an accurate measurement of the code’s runtime.
%%timeit
test = 0
for i in range(100000):
test += 12.45 ms ± 61.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
We can also measure the time of the cell from one iteration using %%time
%%time
test = 0
for i in range(100000):
test += 1CPU times: user 4.93 ms, sys: 0 ns, total: 4.93 ms
Wall time: 4.89 ms
We see a number of different times listed here:
Wall time: This is the time that has passed during the running of the codeCPU time: This is the time that the CPU was busy. This also includes time when the CPU has “swapped” its attention to a different process.user: This is the time that the process has been running on the CPU but outside of the system kernelsys: This is the time taken inside the system kernel. This could indicate that the code requires a lot of system calls rather than calls written by the developer.
As a rule of thumb:
- CPU Time / Wall Time ~ 1. The process spent most of it’s time using the CPU. A faster CPU could improve performance.
- CPU Time / Wall Time < 1. This suggest the process has spent time waiting. This could be resource allocations, network/hardware IO, locks (to prevent data races) etc. The smaller the number, the more time spent waiting. 0.9 would suggest 10% of the time the CPU is idle.
- CPU Time / Wall Time > 1. This suggests that we are utilizing multiple processors when running our code.
If we are running with N processors:
- CPU Time / Wall Time ~ N. The process is well distributed across all CPUs with little to no idle time.
- CPU Time / Wall Time < N. This suggest the process has spent time waiting. This could be resource allocations, network/hardware IO, locks (to prevent data races) etc.
We can use %timeit to time an single line or process, averaging over multiple runs:
print ("This line won't be timed")
# Either will this line
test = np.random.random(1000)
# This line will be timed
%timeit test = np.random.random(1000)This line won't be timed
4.04 µs ± 20.3 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Let’s look at comparing two functions. Consider vector addition. In a pure Python, we would use a for loop to iterate over each element. We could also use numpy’s inbuilt functions to perform the addition.
def add_two_arrays(a : np.ndarray,b : np.ndarray) -> np.ndarray:
"""Add two numpy arrays together using a for loop
Args:
a : array 1 to be added
b : array 2 to be added
Returns:
array of a + b
"""
c = np.zeros(len(a))
for i in range(len(a)):
c[i] = a[i] + b[i]
return c
def add_two_arrays_numpy(a : np.ndarray, b : np.ndarray) -> np.ndarray:
"""Add two numpy arrays together using vectorization
Args:
a : array 1 to be added
b : array 2 to be added
Returns:
array of a + b
"""
c = a + b
return ctest_x = np.random.random(1000)
test_y = np.random.random(1000)
print("Pure Python:")
%timeit test_z = add_two_arrays(test_x, test_y)
print("Numpy:")
%timeit test_z = add_two_arrays_numpy(test_x, test_y)
Pure Python:We see a dramatic improvement by using NumPy arrays to add two vectors together. This is because NumPy is a highly optimized library, with the low-level code written in C++. Is this always the case?
151 µs ± 1.7 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Numpy:
624 ns ± 4.36 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
def time_addition(n):
test_x = np.random.random(n)
test_y = np.random.random(n)
n_repeat = 10
# pure python
t_start = time.time()
for _ in range(n_repeat):
_ = add_two_arrays(test_x, test_y)
t_pure = np.median(time.time() - t_start)
# numpy
t_start = time.time()
for _ in range(n_repeat):
_ = add_two_arrays_numpy(test_x, test_y)
t_numpy = np.median(time.time() - t_start)
return t_pure, t_numpyn_array = np.arange(20)
times_py = np.zeros(n_array.shape)
times_np = np.zeros(n_array.shape)
for i, n in enumerate(n_array):
times_py[i], times_np[i] = time_addition(int(2**n))plt.plot(2 ** n_array, times_py, "C0s:", label = "Pure Python")
plt.plot(2 ** n_array, times_np, "C1o--", label = "Numpy")
plt.loglog()
plt.grid()
plt.legend()
plt.xlabel("Array Length")
plt.ylabel("Run Time [s]");

At very small array sizes the performance is comparable. This is likely due to the overhead of calling the low level NumPy code. The NumPy perfomance saturates around 
It might be easy to assume for the above example that NumPy is always better than pure Python, but this isn’t always the case and we should always consider our specific needs.
If we where writing code to operate on small (O(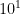
Line profiling
Line profiling is a useful tool for finding bottlenecks within a block of code. There are many profilers one can use:
- cProfiler
- line_profiler
- pprofile
For this example, we’ll use line_profiler. line_profiler comes with some ipython magic functions that make it super easy to use in a jupyter notebook. This can be installed via:
mamba/conda install line_profileror
pip install line_profilerLet’s look at an expensive function that uses a MC method to estimate 
We’re going to throw random points ![x, y \in [0,1]](https://s0.wp.com/latex.php?latex=x%2C+y+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)

The area of a circle is given by:

Since we’re throwing random numbers in the range [0,1], we will fill a quarter of a circle.

Where 

Combing these, we can estimate

One might code this up as such:
def monte_carlo_pi(nsamples):
acc = 0
for i in range(nsamples):
x = np.random.random()
y = np.random.random()
if (x ** 2 + y ** 2) < 1.0:
acc += 1
return 4.0 * acc / nsamples
Let’s select an appropriate number of random samples for testing.
n_range = np.arange(7)
pi_diff = [np.abs(np.pi - monte_carlo_pi(10**n)) for n in n_range]plt.plot(10**n_range, pi_diff)
plt.xlabel("Number of Random Samples")
plt.ylabel("|πNumPy−πMC||πNumPy−πMC||\pi_{NumPy} - \pi_{MC}|")
plt.grid()
plt.xscale('log')
plt.yscale('log')
We can see that as 
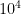
n_total = 10 ** 4How long does this take to run?
%timeit monte_carlo_pi(n_total)6.3 ms ± 47.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
We an also use timeit.repeat to measure the runtime:
n_run = 100
n_repeat = 10
t_original = np.array(
timeit.repeat(f"monte_carlo_pi({n_total})", "from __main__ import monte_carlo_pi", repeat = n_repeat, number = n_run)
) / n_run
print(f"Original Runtime = {np.mean(t_original) : 0.2e} +/- {np.std(t_original) :0.2e} s")Original Runtime = 6.26e-03 +/- 6.13e-05 s
If we want to speed up this calculation, we should first find what is the major bottleneck. For this we’ll use line_profile:
%load_ext line_profiler
%lprun -f monte_carlo_pi monte_carlo_pi(n_total)Timer unit: 1e-09 s
Total time: 0.0126314 s
File: /tmp/ipykernel_146935/1024659408.py
Function: monte_carlo_pi at line 1
Line # Hits Time Per Hit % Time Line Contents
==============================================================
1 def monte_carlo_pi(nsamples):
2 1 902.0 902.0 0.0 acc = 0
3 10001 937704.0 93.8 7.4 for i in range(nsamples):
4 10000 4108430.0 410.8 32.5 x = np.random.random()
5 10000 3825506.0 382.6 30.3 y = np.random.random()
6 10000 2369306.0 236.9 18.8 if (x ** 2 + y ** 2) < 1.0:
7 7911 1388981.0 175.6 11.0 acc += 1
8 1 591.0 591.0 0.0 return 4.0 * acc / nsamples
The above shows a breakdown of where we’re spending time. We have each line of the function broken down. We can see that the allocations of acc and the return of 4.0 * acc / nsamples are expensive operations, but this only happens once per execution. Since these only happen once there may be some “noise” effecting these estimates.
for i in range(nsamples): takes 8% of our time. This is pretty significant. Python is also notoriously bad at looping. If we can avoid looping in Python we should.
We also see that acc += 1 doesn’t happen every iteration, and we spend ~20% of our time checking if (x ** 2 + y ** 2) < 1.0. We can see that the dominate part of the time is spent generating random numbers (x/y = np.random.random()) which takes ~60% of the run time.
If we were looking to speed up this function, we should work target the most expensive parts first, this would suggest targeting:
x = np.random.random()
y = np.random.random()
if (x ** 2 + y ** 2) < 1.0:
Which constitutes 80% or our run time. Since these are ran 10000 times, it might make more sense to somehow only run this once. But how…
def monte_carlo_pi_pure_numpy(nsamples):
# Create random arrays with required number of samples
# Use the highly optimized numpy functions instead of for loop
x = np.random.random(nsamples)
y = np.random.random(nsamples)
# Do the filtering and calculation in the one line
return 4.0 *np.sum((x ** 2 + y ** 2) < 1.0) / nsamplesn_run = 1000
n_repeat = 10
t_optimized = np.array(
timeit.repeat(f"monte_carlo_pi_pure_numpy({n_total})", "from __main__ import monte_carlo_pi_pure_numpy", repeat = n_repeat, number = n_run)
) / n_run
print(f"Optimized Runtime = {np.mean(t_optimized) : 0.2e} +/- {np.std(t_optimized) :0.2e} s")Optimized Runtime = 8.57e-05 +/- 1.13e-06 s
This gives a factor of ~100 improvement in runtime: Let’s rerun the line profiler reports now:
%lprun -f monte_carlo_pi_pure_numpy monte_carlo_pi_pure_numpy(n_total)Timer unit: 1e-09 s
Total time: 0.000211448 s
File: /tmp/ipykernel_146935/764224049.py
Function: monte_carlo_pi_pure_numpy at line 1
Line # Hits Time Per Hit % Time Line Contents
==============================================================
1 def monte_carlo_pi_pure_numpy(nsamples):
2 # Create random arrays with required number of samples
3 # Use the highly optimized numpy functions instead of for loop
4 1 89148.0 89148.0 42.2 x = np.random.random(nsamples)
5 1 35426.0 35426.0 16.8 y = np.random.random(nsamples)
6 # Do the filtering and calculation in the one line
7 1 86874.0 86874.0 41.1 return 4.0 *np.sum((x ** 2 + y ** 2) < 1.0) / nsamples
It would appear y = np.random.random(nsamples) takes less than half the time as x = np.random.random(nsamples). However, rerunning the profile can change this result. This is likely due to noise.
Can we do better?
We’re already using highly optimized NumPy which is based on C/C++ code. However we’re still interpreting slow bytecode at run time and running on one core. We can use numba to “just-in-time” compile the Python code to machine code at runtime. This optimization provides a significant boost in speed.
We can use Numba by decorating functions with the `@jit` decorator.
from numba import jit
@jit
def monte_carlo_pi_pure_numpy_jit(nsamples):
# Create random arrays with required number of samples
# Use the highly optimized numpy functions instead of for loop
x = np.random.random(nsamples)
y = np.random.random(nsamples)
# Do the filtering and calculation in the one line
return 4.0 *np.sum((x ** 2 + y ** 2) < 1.0) / nsamplesAll we’ve done here is add the @jit decorator above our function. This will instruct the Python interpter to use numba to compile the function. Let’s run the function and time it:
t1 = time.time()
monte_carlo_pi_pure_numpy_jit(n_total)
telap = time.time() - t1
print (f"This took {telap}s")This took 0.7720179557800293s
As the phrase just-in-time suggests, the code is only compiled in time for it to be executed. This means that the first time the function is executed, it is first compiled by numba. After the first time, we’ll use the compiled version of the function, not needing to recompile it.
Let’s run the function again:
t1 = time.time()
monte_carlo_pi_pure_numpy_jit(n_total)
telap = time.time() - t1
print (f"This took {telap}s")This took 8.821487426757812e-05s
That’s better!
It is good practice to pre-compile and pre-run the functions before they are actually used. This is especially important if we’re going to be running a long process for the first execution. Using the example above, instead of running with
n_run = 1000
n_repeat = 10
t_jitted = np.array(
timeit.repeat(f"monte_carlo_pi_pure_numpy_jit({n_total})", "from __main__ import monte_carlo_pi_pure_numpy_jit", repeat = n_repeat, number = n_run)
) / n_run
print(f"jitted Runtime = {np.mean(t_jitted) : 0.2e} +/- {np.std(t_jitted) :0.2e} s")jitted Runtime = 5.41e-05 +/- 6.22e-07 s
This gives an additional but only slight improvement over the pure NumPy version. We can improve on this using the parallel = True option when using the @jit decorator:
@jit( parallel = True )
def monte_carlo_pi_pure_numpy_jit_parallel(nsamples):
# Create random arrays with required number of samples
# Use the highly optimized numpy functions instead of for loop
x = np.random.random(nsamples)
y = np.random.random(nsamples)
# Do the filtering and calculation in the one line
return 4.0 *np.sum((x ** 2 + y ** 2) < 1.0) / nsamples
# pre-run to compile
monte_carlo_pi_pure_numpy_jit_parallel(n_total) n_run = 10000
n_repeat = 10
t_jitted_parallel = np.array(
timeit.repeat(f"monte_carlo_pi_pure_numpy_jit_parallel({n_total})", "from __main__ import monte_carlo_pi_pure_numpy_jit_parallel", repeat = n_repeat, number = n_run)
) / n_run
print(f"jitted parallel Runtime = {np.mean(t_jitted_parallel) : 0.2e} +/- {np.std(t_jitted_parallel) :0.2e} s")jitted parallel Runtime = 1.96e-05 +/- 5.77e-06 s
This gives around a factor of 300 improvement in the run time. This value will scale with the number of available CPUs.
Returning to our original example, we can use numba to obtain similar performance as the pure NumPy case:
from numba import prange
@jit(nopython = True, parallel = True)
def monte_carlo_pi_revisit(nsamples):
acc = 0
for i in prange(nsamples):
x = np.random.random()
y = np.random.random()
if (x ** 2 + y ** 2) < 1.0:
acc += 1
return 4.0 * acc / nsamples
monte_carlo_pi_revisit(n_total)Here we’re importing prange. prange works the same as range however it allows the loop to be executed in parallel. If the above was ran with parallel = False then prange would act the same as range.
n_run = 10000
n_repeat = 10
t_jitted_revisit = np.array(
timeit.repeat(f"monte_carlo_pi_revisit({n_total})", "from __main__ import monte_carlo_pi_revisit", repeat = n_repeat, number = n_run)
) / n_run
print(f"jitted parallel no python Runtime = {np.mean(t_jitted_revisit) : 0.2e} +/- {np.std(t_jitted_revisit) :0.2e} s")jitted parallel no python Runtime = 2.10e-05 +/- 4.72e-06 s
Summary
We’ve looked at both how to speed up a simple function by first using pure NumPy, then moving to compiled versions, before moving to a parallel implementation:
speedup = np.mean(t_original) / np.mean(t_optimized)
print (f"Pure NumPy speeds up the code by a factor of {speedup:0.2f}")
speedup = np.mean(t_original) / np.mean(t_jitted)
print (f"Compiled NumPy speeds up the code by a factor of {speedup:0.2f}")
speedup = np.mean(t_original) / np.mean(t_jitted_parallel)
print (f"Parallel and compiled NumPy speeds up the code by a factor of {speedup:0.2f}")
speedup = np.mean(t_original) / np.mean(t_jitted_revisit)
print (f"Parallel and complied python speeds up the code by a factor of {speedup:0.2f}")Pure NumPy speeds up the code by a factor of 73.03
Compiled NumPy speeds up the code by a factor of 115.65
Parallel and compiled NumPy speeds up the code by a factor of 319.28
Parallel and complied python speeds up the code by a factor of 298.48
The compiled and parallel implementations offer the best performance. If we don’t have access to a multi-core system, we achieve x100 performace by simply compiling the function with numba and jit. This is a very low effort way to obtain a huge performance improvement!
This post just looked at run time performance. In a future post we’ll look at how to profile the memory usage of a Python program.